
DeepSeek R1: Pioneering Reasoning in Large Language Models Through Reinforcement Learning
Published:
The development of reasoning capabilities in large language models (LLMs) is a complex yet pivotal frontier in AI research. DeepSeek R1 represents a major leap in this space, introducing innovative methodologies for reasoning-oriented model training. In this post, we’ll explore what makes DeepSeek R1 significant, its architectural innovations, and its implications for the future of AI.
What is DeepSeek R1?
DeepSeek R1 is a first-generation reasoning model designed to enhance the cognitive depth of LLMs. It consists of two variants:
- DeepSeek R1-Zero: Developed purely via reinforcement learning (RL) without any supervised fine-tuning (SFT).
- DeepSeek R1: Builds on R1-Zero by incorporating a small amount of curated cold-start data followed by multi-stage reinforcement learning.
Both models leverage advanced reinforcement learning methodologies to emerge with remarkable reasoning capabilities, overcoming many of the limitations seen in prior LLMs.
Why DeepSeek R1 Matters
1. Revolutionizing Model Training
DeepSeek R1’s use of reinforcement learning (RL) as a standalone training paradigm challenges traditional dependency on vast supervised datasets. By incentivizing reasoning directly, the models autonomously discover complex problem-solving strategies, an approach that mirrors human cognitive learning.
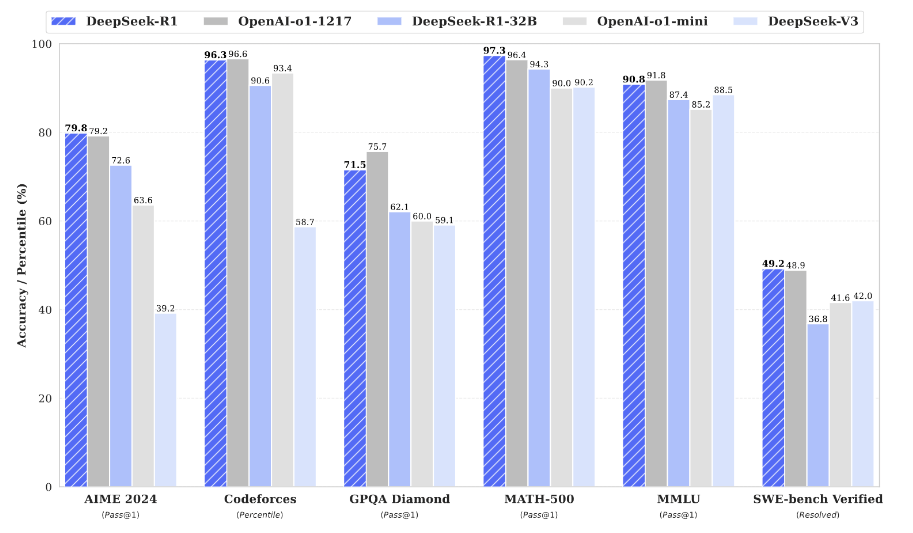
[Figure 1] shows the benchmark performance of DeepSeek-R1.
2. Benchmark-Breaking Performance
DeepSeek R1 outperforms many industry benchmarks, achieving accuracy levels comparable to leading proprietary models such as OpenAI-o1-1217. Key achievements include:
| Task | DeepSeek R1 Performance (Pass@1) | Comparison |
|---|---|---|
| AIME 2024 | 79.8% | Matches OpenAI-o1-1217 |
| MATH-500 | 97.3% | Surpasses others significantly |
| Codeforces | 96.3% percentile | Competitively rated against humans |
3. Distillation of Reasoning
One of DeepSeek R1’s standout features is its ability to distill reasoning into smaller models. This means even models with as few as 1.5 billion parameters can exhibit advanced reasoning capabilities, making sophisticated AI more accessible for real-world applications.
How DeepSeek R1 Achieves Its Results
Reinforcement Learning (RL) with Group Relative Policy Optimization (GRPO)
DeepSeek R1 employs Group Relative Policy Optimization (GRPO) to efficiently optimize performance without requiring large critic models. This enables the model to:
- Adaptively allocate “thinking time” to reasoning tasks.
- Generate sophisticated chain-of-thought (CoT) reasoning trajectories.
Addressing Language Mixing and Readability
Cold-start data fine-tuning ensures DeepSeek R1’s outputs are coherent and user-friendly, even in multi-lingual contexts. By balancing language consistency with reasoning depth, the model improves usability without compromising performance.
Future Potential and Research Directions
DeepSeek R1 sets the stage for an era of reasoning-focused AI. However, the research team highlights key areas for future improvements:
- Enhanced General Capabilities: Extending reasoning to complex multi-turn tasks and structured outputs.
- Better Language Support: Addressing language mixing in less common languages.
- Optimized Prompt Sensitivity: Refining performance in varied prompt scenarios.
- Expanded Software Engineering Applications: Improving performance on engineering-related coding tasks.
Why This Matters for AI Researchers and Developers
DeepSeek R1 exemplifies the power of RL in advancing LLM reasoning. For developers, this opens the door to more effective reasoning-based applications, from educational tools to advanced coding assistants. For researchers, it underscores the untapped potential of reinforcement learning and distillation in shaping the future of LLMs.
Conclusion
DeepSeek R1 is not just another step in LLM evolution—it is a paradigm shift. Its innovative training methods, groundbreaking results, and accessible smaller models signify a future where AI reasoning becomes both scalable and impactful. As open-source checkpoints for models and APIs become available, we encourage the community to explore the potential of DeepSeek R1 for their own projects.
References
- DeepSeek R1 Paper - Full Text